Il filesystem10.1 File e directoryUn file e' essenzialmente un contenitore di dati omogenei e puo' contenere del testo (una lettera) o dati binari (un file musicale, un' immagine, un video, un programma). Il nome di un file puo' contenere caratteri alfabetici, numeri, caratteri di sottolineatura o di punteggiatura e puo' essere lungo al massimo 256 caratteri (come per Windows). Il nome di un file non puo' iniziare con un numero e non puo' contenere caratteri particolari come punti interrogativi, spazi o asterischi (perche' questi caratteri hanno dei significati particolari per il sistema). In realta' e' sempre possibile creare un nome contenente caratteri speciali come ad esempio 'pippo*' ma per evidenti motivi e' meglio evitare una pratica del genere. Linux e' un sistema case sensitive, cioe' sensibile ai caratteri minuscoli e maiuscoli. Cio' significa che per Linux 'CIAO', 'ciao', 'CiAo' e 'ciAO' sono 4 file diversi. Questo non e' vero per altri sistemi come Windows, dove 'CIAO' o 'ciao' rappresentano sempre lo stesso file. Esistono 4 tipi di file: i file comuni, le directory, i file a caratteri e di file a blocchi. In un sistema Linux ogni file viene collocato all'interno di una directory (cartella) ben precisa. Una directory (o cartella o folder, come viene chiamata nei sistemi Windows) e' essenzialmente un contenitore di file. Un filesystem strutturato secondo un sistema di directory puo' essere assimilato ad una libreria, dove ogni scaffale che identifica una categoria (narrativa, umorismo, cucina, storia) rappresenta la directory stessa, mentre i libri in esso riposti rappresentano i file. Una directory puo' contenere file ma puo' contenere anche altre directory (che come abbiamo visto sono un particolare tipo di file). Una directory contenuta all'interno di un'altra directory viene definita subdirectory o sottodirectory (il primo termine sarebbe piu' corretto ma in Italia abbiamo ormai acquisito la pessima abitudine di italianizzare i termini inglesi creandone di nuovi come ad esempio shiftare, swappare, loggare, mecciare, ciattare, ceccare etc ;o) pertanto la seconda locuzione e' quella piu' usata). Un filesystem composto da directory puo' anche essere paragonato ad un albero, dove la directory principale o root o radice o /, rappresenta il tronco, mentre le sottodirectory rappresentano i rami dell'albero. Partendo dalla directory radice si puo' arrivare ad un file qualsiasi all'interno di una qualsiasi directory, cosi' come partendo dal tronco si puo' arrivare ad una foglia qualsiasi di un ramo qualsiasi dell'albero. Ad esempio e' possibile avere una directory 'Cucina' al cui interno si trovano la directory 'Ricette' e la directory 'Vini':
A sua volta la directory 'Ricette' puo' contenere la directory 'Primi', la directory 'Secondi' e la directory 'Contorni':
e cosi' via. E' possibile
avere un infinito numero di directory una all'interno dell'altra,
come una sorta di sistema di bambole matrioska. Ad ogni utente
viene assegnata una directory personale, all'interno della quale
e' possibile creare altre directory.
All'interno della directory usr sono presenti solitamente le seguenti directory:
Alcune directory pero' sono presenti solo per motivi di compatibilita' e in realta' non vengono usate solitamente. Nei prossimi paragrafi verranno illustrate in dettaglio. // e' la directory principale (o di directory root). Contiene il kernel predefinito (in Linux esiste un kernel di default e vari kernel alternativi. All'avvio del sistema e' possibile decidere quale versione di kernel caricare. Nel caso non venisse specificata alcuna versione, il sistema carichera' il kernel presente in questa directory) e non dovrebbero esserci altri file. binIn questa directory sono contenuti tutti i programmi per la gestione del sistema. bootQui sono presenti i kernel alternativi ed altri file utilizzati da LILO. devdev sta per devices, letteralmente dispositivi. In questa directory sono contenuti i file di device, ossia i file necessari per l'utilizzo dei vari dispositivi (monitor, stampanti, dischi etc). I vari dispositivi sono visti da Linux come dei file e possono essere letti e scritti come normalissimi file. Un file speciale contenuto all'interno di questa directory e' il file null. Il file null e' un file di dimensione infinita e qualunque cosa venga scritta all'interno di questo file viene scartata. E' paragonabile ad un cestino di dimensioni infinite. etcQui sono presenti tutti i file di configurazione del sistema, di LILO ed il database degli utenti (dove sono registrate la userid e la password di ciascun utente). homeE' la directory che contiene tutte le directory personali di tutti gli utenti. Se un sistema Linux e' accessibile agli utenti Paolo, Rita e Marco, in questa directory saranno presenti le directory Paolo, Rita e Marco. Quando un utente si collega al sistema (effettua cioe' il login) potra' accedere unicamente alla propria directory (Marco accedera' alla directory Marco ma non potra' accedere alla directory Paolo, cosi' come Rita accedera' alla directory Rita ma non potra' accedere alla directory Marco e via dicendo) libContiene tutte le librerie condivise del sistema. lost foundIn caso di interruzione della corrente elettrica, e' possibile che vengano persi i dati sui quali si stava lavorando. Al riavvio del sistema viene effettuato un controllo del disco per verificare la presenza di errori e di dati persi. E' in questa directory che vengono raccolte le parti di file recuperate. mntE' la directory di mount. Per collegare un'unita' di memorizzazione dati al sistema (disco, CD-Rom, nastro etc) occorre effettuare una operazione di mount (verra' vista in seguito). Generalmente le varie unita' vengono montate all'interno di questa directory (anche se e' possibile montarle in directory differenti). procQuesta e' un' altra directory particolare: contiene infatti un filesystem virtuale. Non e' infatti un filesystem vero e proprio, in quanto viene creato dal kernel dinamicamente istante per istante, in memoria e non sul disco. Al suo interno sono contenute le informazioni relative al sistem (originariamente erano contenute esclusivamente le informazioni relative ai vari processi in esecuzione, da cio' il nome proc). optContiene applicazioni particolari (di solito KDE, GNOME ed altre). rootE' la directory home dell'amministratore del sistema (anche l'amministratore e' un utente del sistema e possiede una directory personale). sbinContiene programmi di sistema eseguibili solo dall'amministratore del sistema come ad esempio fdisk o fsck. tmpContiene dei file temporanei. usrIn questa directory sono contenute tutte le applicazioni ed i file che non servono per la gestione del sistema (come X-Windows, Latex etc). Qui vengono inoltre installati i vari pacchetti software. All'interno di questa directory sono inoltre presenti altre directory come X11R6, bin, doc, man etc. varE' la directory dei file variabili, cioe' quei file che non hanno una lunghezza predefinita e variano nel tempo. Qui sono presenti ad esempio i file di spool (i file di stampa che sono in coda), i fax, i messaggi da inviare, i file di log etc. Come abbiamo visto all'interno della directory usr sono presenti a loro volta altre directory tipiche dei sistemi Linux. Vediamo quindi anche la struttura della directory usr. X11R6I caratteri sono tutti maiuscolo. E' la directory contentente i file del sistema X-Windows. docContiene file di documentazione varia. inlcudeContiene i file header per il preprocessore C e C (cioe' i file .h) localContiene tutte le applicazioni ed i file locali. manContiene il manuale online di Linux. Si tratta di file di testo che spiegano l'uso dei vari comandi di Linux. shareContiene file indipendenti dall'architettura suddivisi per architetture (Sparc, RS6000 etc). srcContiene i sorgenti dei programmi del sistema. Nella sottodirectory 'linux' sono presenti i sorgenti dek kernel. spoolE' mantenuta solo per motivi di compatibilita'. In realta' contiene un link alla directory /var/spool. 10.3 I simboli che identificano le directoryLe directory che compongono il filesystem di Linux possono essere esplorate utilizzando due o tre comandi basilari la cui conoscenza e' veramente obbligatoria. Prima di vedere tali comandi pero', occorre apprendere alcune convenzioni tipiche degli ambienti Unix ma acquisite successivamente anche negli ambienti DOS. In ambiente Linux (ma anche Unix e DOS) la directory corrente e' rappresentata da simbolo '.' (punto), mentre la directory a livello immediatamente superiore e' rappresentata dai simboli '..' (punto punto senza spazi). La directory iniziale, cioe' la directory che contiene tutte le altre sottodirectory e' rappresentata dal simbolo '/' (barra o slash). Occorre fare attenzione a non confondere il carattere '/' (slash) dal carattere '\' (backslash). Non sono la stessa cosa! Sulla tastiera infatti sono presenti entrambi: il carattere utilizzato in ambiente Linux e' '/', cioe' quello che si trova sopra il numero 7 della tastiera. Questo a differenza del DOS che, come sanno i vecchi utilizzatori di PC, utilizza il carattere '\' (anche Windows usa il carattere '\'). La directory genitore di tutte le altre directory, cioe' la directory '/' e' detta anche directory root. Per specificare una directory che si trova all'interno di un'altra directory occorre indicare il path (o pathname), cioe' il percorso completo, separando le due directory con il simbolo '/'. Ad esempio, per specificare la directory 'Ricette' che si trova all'interno della directory 'Cucina', occorre scrivere: /Cucina/Ricette Dove il primo / indica che il percorso parte dalla directory principale o root (/) ed il secondo indica che la directory Ricette si trova all'interno della directory Cucina. Qualora all'interno della directory Ricette fosse presente una terza sottodirectory, sarebbe presente un altro carattere /. Ad esempio, per specificare la directory 'Secondi' che si trova all'interno della directory Ricette che a sua volta si trova all'interno della directory Cucina, occorre scrivere: /Cucina/Ricette/Secondi Attenzione: in questi esempi il primo carattere di ogni directory e' maiuscolo; occorre ricordarsi che Linux e' case sensitive percio' la directory Cucina e' una directory diversa dalla directory cucina! Se nel PC e' presente la directory Cucina, specificando un path come questo: /cucina/Ricette si otterrebbe un messaggio di errore, in quanto Linux non sarebbe in grado di trovare una directory 'cucina' perche' il primo carattere digitato e' minuscolo, mentre sul PC e' presente una directory Cucina con il primo carattere maiuscolo. Il messaggio di errore ottenuto da Linux e' in inglese, ma il significato e': 'file non trovato'. 10.4 Spostarsi tra le directoryPer esplorare le directory di Linux occorre conoscere 2 o 3 comandi basilari: il primo e' senza dubbio il comando PWD. PWD sta per Print Working Directory, cioe' stampa la directory corrente. Attenzione: generalmente i comandi Linux sono composti da caratteri minuscoli, percio' il nome corretto del comando e' pwd. Digitando PWD otterremo il solito messaggio di errore in quanto non esiste un file di nome PWD. Digitando il comando pwd e premendo invio, il sistema rispondera' visualizzando il nome della directory di lavoro, cioe' della directory in cui ci si trova. Il secondo comando basilare da conoscere e' il comando LS. LS sta per LiSt directory, cioe' elenca il contenuto della directory e serve per visualizzare l'elenco dei file contenuti all'interno di una directory. Il terzo comando da conoscere assolutamente e' il comando CD. CD sta per Change Directory, cioe' cambia directory, e serve per spostarsi da una directory all'altra. Ogni comando Linux e' in realta' un programma che accetta anche dei parametri. I parametri servono per specificare delle opzioni aggiuntive. Alcuni comandi come ad esempio cd, prevedono dei parametri obbligatori. Il comando cd serve per spostarsi all'interno di un'altra directory, ma per far cio' occorre specificare la directory verso la quale ci si vuole spostare. Ad esempio, supponendo una situazione del genere: /cucina/ricette/secondi Se ci si trova all'interno della directory /cucina, per entrare all'interno della directory secondi, occorrera' digitare: cd ricette/secondi dove ricette/secondi e' il nome della directory di arrivo, ed e' anche il parametro obbligatorio da specificare per il comando cd. Combinando i comandi pwd e cd, possiamo verificare l'operato di entrambi. Vediamo un esempio:
pwd (comando digitato) Nell'esempio appena visto, il comando pwd visualizza il nome della directory corrente (/cucina/ricette), successivamente il comando cd permette di posizionarsi sulla directory /cucina/ricette/secondi. Infine il comando pwd mostra nuovamente la situazione, visualizzando il nome della directory che abbiamo raggiunto. Dopo aver digitato un comando occorre ovviamente premere il tasto INVIO. E' possibile spostarsi da una directory all'altra utilizzando i caratteri '/', '.' e '..'. Ad esempio, se ci si trova all'interno della directory secondi e si vuole tornare nella directory immediatamente superiore, si puo' digitare il comando cd con il parametro '..' e cioe': cd .. come abbiamo visto prima infatti, '..' rappresenta la directory che si trova al livello immediatamente superiore. Attenzione: tra cd e .. occorre lasciare uno spazio, altrimenti il sistema visualizzerebbe un messaggio di errore. Cosi' facendo infatti, il sistema andrebbe infatti a cercare un comando di nome 'cd..' che ovviamente non esiste. Inserendo uno spazio tra cd e .. il sistema e' in grado di capire che cd e' il comando da eseguire e .. e' il parametro da passare al comando. Cd e' un comando ma e' anche un programma come abbiamo visto. Il programma cd quindi, ricevendo .. come parametro, ci portera' alla directory che si trova al livello immediatamente superiore. Per cambiare directory, e' possibile usare il path (percorso) relativo o quello assoluto. Gli esempi appena visti usano il path relativo. Nel caso precedente, la directory 'secondi' si trova all'interno della directory 'ricette' che a sua volta si trova all'interno della directory 'cucina'. La directory cucina infine, si trova all'interno della directory root (radice), cioe' la directory '/'. Supponendo di essere posizionati all'interno della directory /, per indicare la directory secondi occorrera' digitare: cucina/ricette/secondi. Supponendo di essere posizionati all'interno della directory cucina, occorrera' digitare: ricette/secondi. Supponendo di essere posizionati all'interno della directory ricette, occorrera' scrivere: secondi. In altre parole, la directory nella quale ci si trova (directory corrente o di lavoro) viene considerata dal sistema come punto di partenza e pertanto non e' necessario digitarne il nome. Supponendo pero' di essere posizionati all'interno di una directory esterna al path /cucina/ricette/secondi, ad esempio la directory /documenti/lettere/carla per indicare la directory secondi, occorrera' usare il path assoluto, il che significa che sara' necessario specificare il percorso completo della directory secondi e cioe': /cucina/ricette/secondi. Esempi:
Ci si trova posizionati all'interno della directory /documenti/lettere/carla:
/documenti/lettere/carla_ il comando ls cucina visualizzera' il contenuto della directory cucina, cioe' i file primi, secondi ed antipasti. In realta' primi secondi ed antipasti sono delle directory mentre miaricetta e ristoranti sono dei semplici file di testo, ma, come abbiamo visto, una directory non e' altro che un tipo speciale di file ed il comando ls non fa distinzioni tra i tipi di file. Il comando ls visualizzera' qiundi qualsiasi file, sia esso un file di testo, un file directory od un qualsiasi altro tipo di file. Il comando ls, come qualsiasi altro comando, accetta i caratteri . e .., percio' per visualizzare il contenuto della directory nella quale ci si trova, si potra' digitare: ls . in quanto '.' rappresenta la directory corrente. Allo stesso modo per visualizzare il contenuto della directory immediatamente superiore si potra' digitare: ls .. in realta' non e' necessario digitare ls . per visualizzare il contenuto della directory corrente, in quanto se non specificata alcuna directory, il sistema utilizzera' la directory corrente. Percio' il comando ls da solo e senza altri parametri visualizza il contenuto della directory in cui ci si trova: ls quindi i comandi seguenti producono lo stesso risultato:
ls In tutti questi esempi visti fino ad ora, per motivi di semplicita' non sono stati illustrati i possibili parametri utilizzabili dai comandi pwd, cd ed ls. Il comando ls ad esempio accetta un incredibile numero di parametri. Ad ogni modo i parametri piu' usati verranno illustrati successivamente nei prossimi capitoli. Un altro piccolo particolare che e' stato omesso negli esempi precedenti e che verra' omesso anche in futuro e' il prompt di Linux. Ecco infatti un reale esempio di comando ls:
mau@localhost mau ]$_ 'dove mau@localhost mau ]$' e' il prompt mentre '_' e' il cursore lampeggiante. Ovviamente dopo aver digitato qualsiasi comando per eseguirlo realmente occorre premere il tasto INVIO: anche questo particolare e' stato omesso dandolo per scontato. ;o) 10.5 I permessi di accesso sui filePer visualizzare a video l'elenco dei file contenuti all'interno di una directory occorre usare il comando ls. Infatti ls sta per list (elenca). Il comando ls accetta varie opzioni come -a, -l o -i. L'opzione -l (l sta per long, cioe' lunga, estesa) permette di visualizzare alcuni dettagli importanti di ciascun file. Percio' il comando ls da solo visualizza l'elenco dei file di una directory ma usato con l'opzione -l visualizza alcuni importanti dettagli. Ad esempio:
ls -l Il nome del file e' l'ultima informazione presente in ogni riga. Cosa significano allora tutte le altre informazioni? Il primo carattere indica il tipo di file e puo' essere un trattino o una 'd'. Il trattino indica un comune file, mentre la 'd' indica che si tratta di una directory. In realta' i tipi di file possibili sono 8:
- file regolare Gli altri 9 caratteri indicano i permessi di accesso al file. Segue il numero di link, il nome del proprietario del file, il nome del gruppo a cui appartiene il proprietario, le dimensioni in byte, la data e l'ora dell'ultima modifica ed infine il nome del file stesso. Nell'esempio precedente il file 'file4' e' lungo 210 byte (210 caratteri) e' stato modificato il 18 febbraio alle ore 12:10. Il suo proprietario e' mau che appartiene al gruppo utenti. Questo file ha un unico link e non e' una directory ma un comune file. Qualsiasi file puo' essere acceduto o meno da 3 categorie di utenti: il proprietario del file, il gruppo di utenti a cui appartiene il proprietario ed infine tutti gli altri utenti che posseggono un account sul sistema. Un file puo' essere letto o visualizzato se ne si possiede il permesso in lettura; puo' essere sovrascritto, cancellato o modificato se se ne possiede il permesso in scrittura; puo' essere eseguito se se ne possiede il permesso in esecuzione. I permessi di accesso al file sono 9 caratteri suddivisi in blocchetti di 3. I primi 3 caratteri sono relativi al proprietario del file, i successivi 3 sono relativi al gruppo al quale appartiene il proprietario e gli ultimi 3 sono relativi a tutti gli altri utenti del sistema. Ogni terna puo' contenere i caratteri '-', 'r', 'w' o 'x'. Il carattere '-' disabilita un permesso. Il primo carattere di ciascuna terna puo' assumere i valori '-' o 'r'. Il carattere 'r' indica la possibilita' di leggere il file (r sta per read, cioe' lettura) mentre il carattere '-' al contrario indica che la lettura di tale file non e' possibile. Il secondo carattere di ciascuna terna puo' assumere i valori '-' o 'w'. Il carattere 'w' indica la possibilita' di scrivere il file (w sta per write, cioe' scrittura). Percio' la presenza di una 'w' indica che il file e' scrivibile mentre la presenza del carattere '-' indica che tale file non puo' essere sovrascritto o modificato. Infine il terzo carattere di ciascuna terna puo' assumere i valori '-' o 'x'. Il carattere 'x' indica la possibilita' di eseguire il file (x sta per eXecute, cioe' esecuzione). Al solito il carattere '-' indica che tale file non e' eseguibile mentre il carattere 'x' lo rende eseguibile. Se osserviamo la prima terna allora stiamo considerando i permessi di accesso al file posseduti dal proprietario, se osserviamo la seconda terna stiamo considerando i permessi posseduti dal gruppo a cui appartiene il proprietario ed infine, se osserviamo la terza terna, stiamo considerando i permessi di accesso posseduti da tutti gli altri utenti su tale file. Nell'esempio precedente il file 'file4' e' di proprieta' dell'utente mau. L'utente mau puo' leggere tale file (carattere 'r' presente), puo' sovrascriverlo o modificarlo (carattere 'w' presente) ma non puo' eseguirlo (carattere 'x' non presente). Il gruppo utenti (a cui appartiene mau) puo' invece leggere tale file ed eseguirlo, ma non puo' modificarlo. Tutti gli altri utenti del sistema non possono ne' vedere ne' scrivere ne' eseguire il file 'file4'. Un file che puo' essere visto, modificato ed eseguito da qualsiasi utente del sistema avra' tutti i permessi di accesso abilitati, percio' le tre terne saranno valorizzate cosi': rwxrwxrwx. Cio' significa infatti che il proprietario del file lo potra' leggere scrivere ed eseguire, ma anche il gruppo a cui appartiene il proprietario potra' leggere, scrivere ed eseguire tale file; stessa cosa per tutti gli altri utenti, che potranno leggere, scrivere ed eseguire il file. Inizialmente un file contenuto all'interno di una directory eredita i permessi che possiede la directory (che come ricordiamo e' essa stessa un file) ma e' possibile cambiare tali permessi mediante il comando chmod. L'utente root o supervisore e' il proprietario di tutti i file del sistema, pertanto puo' leggere, scrivere ed eseguire qualsiasi file. Inoltre l'utente root puo' modificare i permessi dei file in modo da allargare o restringere l'accesso ad alcuni file agli altri utenti del sistema. Generalmente l'utente medio possiedera' una propria directory (directory home) all'interno della quale potra' creare, modificare eseguire e leggere qualsiasi file. L'accesso a file contenuti all'interno di altre directory esterne alla directory home sara' pertanto inibito. Cio' avviene per motivi di sicurezza, in quanto in caso contrario un utente medio potrebbe accidentalmente distruggere alcuni file di sistema vitali. Al contrario l'utente root in quanto amministratore del sistema deve poter accedere a qualsiasi file. Per evitare di cancellare file importanti accidentalmente, e' utile collegarsi al sistema in qualita' di utente root per il tempo minimo indispensabile a svolgere operazioni di amministrazione mentre per le operazioni di routine quotidiane quindi e' consigliabile collegarsi come semplice utente. Ovviamente un utente che non possiede il permesso di lettura su un file, non potra' nemmeno cambiarne i permessi di accesso. Per modificare i permessi di accesso di un file occorre usare il comando chmod. Tale comando accetta due argomenti: un elenco di variazioni di permessi ed un elenco di file sui quali agire. Per abilitare un permesso occorre usare il simbolo ' ' affianco al tipo di permesso che si desidera modificare. Ad esempio la stringa ' w' abilita il permesso di scrittura mentre la stringa ' x' abilita il permesso di esecuzione. Al contrario per disabilitare un permesso occorre usare il simbolo '-'. E' possibile usare una qualsiasi combinazione di questi simboli. Ad esempio, il comando: chmod w-x dati abilita la scrittura e disabilita l'esecuzione del file 'dati' per tutti gli utenti. Per specificare la tipologia di utenti ai quali abilitare o disabilitare dei permessi esistono 3 simboli: 'u', 'g' ed 'o'. Il simbolo 'u' sta per user ed indica il proprietario del file, il simbolo 'g' sta per group ed indica il gruppo di utenti del quale fa parte il proprietario ed infine 'o' sta per other, cioe' tutti gli altri utenti. Il simbolo che specifica la categoria di utenti per i quali si desidera modificarne i permessi va specificato prima degli altri simboli. Ad esempio, il comando: chmod g w-x dati abilita il gruppo di utenti del quale fa parte il proprietario del file per la scrittura e li disabilita per l'esecuzione. Per abilitare piu' permessi non occorre ripetere il simbolo ' ' piu' volte, cosi' come non e' necessario per il simbolo '-'. Ad esempio per abilitare sia la lettura che la lettura si puo' scrivere rw mentre per abilitare in lettura e disabilitare la scrittura e l'esecuzione occorrera' scrivere r-wx e cosi' via. Se non viene specificata alcuna categoria di utenti si intende modificare i permessi per tutte le categorie. Per specificare tutte le categorie si puo' usare anche il simbolo 'a' , tale simbolo infatta sta per all, cioe tutti. E' da notare che tra i vari simboli non esiste alcuno spazio, occorre infatti scrivere tutti i simboli uno affianco all'altro senza interporre spazi: in caso contrario il sistema rispondera' con un messaggio di errore. Questo modo di specificare i permessi di accesso sui file utilizza dei simboli, percio' viene definito simbolico ma non e' l'unico modo possibile: esiste infatti un altro modo definito assoluto. Il modo assoluto utilizza le cosidette maschere binarie. E' possibile specificare i permessi per ogni categoria di utenti singolarmente usando il metodo simbolico ma e' anche possibile specificare tutti i permessi di tutte le categorie di utenti contemporaneamente usando le maschere binarie. Il vantaggio delle maschere binarie e' la possibilita' di cambiare tutti i permessi usando un solo comando, lo svantaggio e' minore semplicita' d'uso. Infatti il metodo simbolico fa uso di simboli che sono abbastanza facili da ricordare (r per lettura, w per scrittura e via dicendo). Il metodo assoluto al contrario fa uso di maschere binarie. In una maschera binaria le tre categorie di utenti ossia le tre terne di simboli diventano 3 cifre in formato ottale, nel senso che ciascuna categoria e' rappresentata da un numero in base 8. Ogni numero ottale e' equivalente ad un numero di 3 cifre binarie:
0 - 000 Attenzione a non fare confusione: 1, 2, 3, 4 etc. non sono cifre decimali ma sono cifre ottali! Cio' signfica che nel sistema ottale non esiste il simbolo '8' ne' tantomeno il simbolo '9' caratteristici del sistema decimale. Infatti 8 nel sistema ottale si scrive cosi': 10. Nel sistema binario, cioe' in base 2, non esistono 10 simboli come ne sistema decimale, ne' 8 simboli come nel sistema ottale, ma 2 simboli: 0 ed 1. Ad ogni modo come si puo' vedere dalla tabella esposta sopra, la cifra ottale 0 corrisponde alla cifra binaria 000 mentre la cifra ottale 4 ad esempio, corrisponde alla cifra binaria 100. Percio' considerando ciascuno di questi 3 numeri binari come uno switch, cioe' un interruttore che puo' essere acceso o spento, possiamo abilitare o disabilitare un permesso. Il primo numero corrisponde al permesso di lettura, il secondo al permesso di scrittura ed il terzo al permesso di esecuzione. Il numero zero corrisponde all'interruttore spento, cioe' ad un permesso disabilitato, mentre il numero 1 corrisponde all'interruttore acceso, cioe' ad un permesso abilitato. Capito cio', e' facile osservare come la cifra ottale 5 ad esempio, corrisponda alla cifra binaria 101, cioe' primo interruttore acceso, secondo interruttore spento e terzo interruttore acceso che tradotto in altri termini significa lettura abilitata, scrittura disabilitata ed esecuzione abilitata. Cosi' 000 disabilita tutti i permessi mentre 111 al contrario li abilita tutti. Tradotto in base ottale significa che 0 disabilita tutti i permessi mentre 7 li abilita tutti, 4 abilita solo la lettura, 1 solo l'esecuzione e cosi' via. Ecco la corrispondenza con i simboli visti precedentemente:
0 - 000 - --- A questo punto risulta evidente che per rappresentare le 3 terne corrispondenti alle tre categorie di utenti sono sufficienti 3 cifre ottali. La prima cifra ottale infatti e' relativa al proprietario del file, la seconda al gruppo a cui appartiene e la terza a tutti gli altri utenti del sistema. Usando questo sistema con 000 disabilitiamo tutti i permessi a tutti gli utenti proprietario compreso (non consigliabile) ;o) mentre con 777 abilitiamo tutti i permessi a tutti gli utenti (altamente non consigliabile) ;o) Con tale sistema e' possibile ad esempio fornire tutti i permessi al proprietario del file e permettere unicamente la lettura del file stesso a tutti gli altri utenti specificando unicamente la cifra 744. Calcolare di volta in volta le cifre ottali a partire dalla maschera binaria non e' molto comodo ma esiste in realta' un comodo trucchetto per ovviare a questo problema. Consideriamo la seguente tabella:
4 - 100 - r-- la cifra ottale 4 abilita il permesso in lettura, la cifra 2 il permesso in scrittura e la cifra 1 il permesso in esecuzione. Bene, a questo punto per ricavare tutte le combinazioni di permessi possibili e' sufficiente sommare queste 3 cifre ottali. Ad esempio, per abilitare lettura e scrittura occorre sommare 4 e 2 per ottenere 6 (che come si puo' osservare nella tabella precedente corrisponde proprio alla stringa 'rw-' cioe' lettura e scrittura abilitate ed esecuzione disabilitata). Per abilitare lettura ed esecuzione e' sufficiente sommare 4 ad 1 per ottenere 5 (cioe' 'r-x'). Alla luce di tutto cio', per abilitare tutti i permessi al proprietario del file 'dati' e permettere a tutti gli altri utenti solo la lettura e l'esecuzione occorrera' usare il comando chmod in questo modo: chmod 755 dati 10.6 I permessi di accesso sulle directoryCome gia' detto le directory sono esse stesse dei file anche se un po' speciali. Conseguentemente e' evidente che e' possibile specificare i permessi di accesso anche per le directory. Esistono comunque delle sottili differenze. Il permesso di lettura su una directory infatti permette di elencare tutti i file contenuti all'interno, permette cioe' di leggerne il contenuto. Il permesso di scrittura permette di aggiungere nuovi file nella directory, permette cioe' di scrivere al suo interno. Il permesso di esecuzione infine, permette di accedere all'interno della directory. La conseguenza logica di cio' e' che se un file leggibile, scrivibile ed eseguibile viene posto all'interno di una directory che non e' accessibile (perche' ha il permesso di esecuzione disabilitato) il file stesso diventa inaccessibile! Per accedere ad un file pertanto, non e' sufficiente abilitarne i permessi ma occorre che la directory che lo contiene, cosi' come la directory genitrice e tutte le altre directory padre siano abilitate in esecuzione. Non occorre che tali directory siano abilitate anche in lettura. In questo modo si potra' accedere al file accedendo a tutte le directory del percorso senza pero' poter visionare il contenuto di tutte le directory. Ad esempio il file : /home/mau/guida.html puo' essere accessibile a tutti gli utenti del sistema se guida.html ha il permesso di lettura abilitato, se la directory mau ha il permesso di esecuzione abilitato per tutti gli utenti e se la directory home ha il permesso di esecuzione abilitato per tutti gli utenti. L'utente Francesca pertanto potra' leggere il file guida.html tranquillamente, ma non potra' elencare il contenuto della directory mau ne' tantomeno quello della directory home. 10.7 Cambiare il proprietario od il gruppo di un fileAnche se un utente puo' accedere ad un file, solo il prorpietario puo' cambiarne i permessi. Se si vuole quindi cedere il controllo di un file ad un altro utente, occorre cambiarne il proprietario. Per cambiare il proprietario di un file occorre usare il comando chown. Chown sta per 'change owner', cioe' cambia proprietario. Il comando chown accetta due argomenti il primo che e' il nome del nuovo proprietario e il secondo che e' il nome di un file o un elenco di file. Ad esempio per cambiare il proprietario di guida.htm occorre scrivere: chown francesca guida.html Se visualizziamo il file guida.html prima del comando chown infatti, otteniamo:
ls -l guida.html ma una volta eseguito il comando chown avremo:
ls -l guida.html Come si puo' vedere il proprietario di guida.html da mau e' diventato francesca. Allo stesso modo e' possibile cambiare il gruppo su un file utilizzando questa volta il comando chgrp. Il comando chgrp sta per 'change group' cioe' cambia gruppo ed accetta 2 argomenti: il nuovo gruppo ed il file (o l'elenco di file) che deve essere modificato. Attenzione: i comandi chmod, chown e chgrp non hanno effetto su filesystem di tipo FAT (opzione -t vfat del comando mount). Questo perche' il filesystem di tipo FAT non supporta i permessi sui file come Linux. Quindi, nel caso si abbia un sistema con dual boot dove convivono Linux e Windows nello stesso disco e si tenti di eseguire il comando chmod, si otterra' il messaggio di errore: 'operation not permitted'. In altre parole una partizione Windows avra' root come proprietario di default. Cio' implica che i file copiati da partizione Linux a partizione Windows vedranno modificato il nome del proprietario in root. Percio' accedendo ad un sistema Linux come utente generico, non avremo accesso alla partizione contenente Windows! Per ovviare al problema e' possibile montare la partizione Windows cambiando il proprietario da root ad utente generico. Ad ogni modo cio' non e' consigliabile per ovvi motivi di sicurezza. 10.8 I dispositivi ed il comando mountGeneralmente ogni file in un sistema Linux si trova all'interno di una directory. Il sistema di file di Linux (filesystem) e' percio' costituito da un insieme di directory e sottodirectory una all'interno dell'altra e formano logicamente una struttura gerarchica ad albero. Esiste infatti una directory radice (o root) cioe' la directory '/' dalla quale si ramificano tutte le altre sottodirectory. I file contenuti nel filesystem di Linux possono risiedere fisicamente tutti all'interno dello stesso dispositivo di memorizzazione - tipicamente il disco fisso - o su piu' supporti fisici distinti come ad esempio CD-Rom, floppy disk, nastri, unita' di memorizzazione ottica, unita' disco supplementari e via dicendo. Ciascuno di questi dispositivi contiene al suo interno un proprio filesystem (o anche piu' di uno) cioe' una propria struttura ad albero. Il filesystem contenuto in un dispositivo puo' essere lo stesso di quello contenuto nel disco dove risiede il sistema oppure puo' essere diverso. Per poter accedere al filesystem del dispositivo occorre collegare fisicamente il dispositivo al sistema ma occorre anche collegare il suo filesystem al filesystem generale dove risiede il sistema. Si puo' pensare al filesystem del dispositivo aggiuntivo come ad una sorta di sottoalbero che deve essere collegato all'albero generale. Tale operazione di collegamento prende il nome di mount. L'operazione di mount cioe' collega un dispositivo al sistema ed e' un'operazione eseguibile unicamente dall'utente root. Un utente generico pertanto non puo' eseguire tale operazione. Cio' e' logico in quanto l'operazione di manutenzione ed amministrazione del sistema e' compito dell'utente root (supervisore) che e' appunto l'amministratore del sistema. Con il comando mount occorre specificare il tipo di dispositivo da collegare al sistema ed il punto di mount, cioe' la directory che fungera' da radice per il sottoalbero contenuto nel dispositivo. Con il comando di mount si puo' collegare anche un filesystem diverso da quello di Linux contenuto magari nello stesso disco fisico ma in una partizione diversa. Questo e' tipico dei sistemi multiboot dove nello stesso disco risiedono due o piu' sistemi operativi (tipicamente Linux e Windows). A differenza dei sistemi tipo Windows occorre percio' ricordare che anche per accedere ai dati contenuti in un normale floppy disk o di un CD-Rom occorre prima effettuare l'operazione di mount. Inoltre se occorre leggere piu' floppy disk o piu' CD-Rom, occorre montare e 'smontare' ogni volta ciascun dispositivo. L'operazione inversa al mount e' l'operazione di umount. In realta' cio' non e' sempre vero in quanto per ovvi motivi di comodita' e' stato ideato un tipo particolare di mount, il supermount. Si tratta in realta' di un programma che rimane sempre attivo nel sistema anche se in stato letargico. E' un programma che sonnecchia ma che si sveglia immediatamente non appena viene inserito un nuovo dispositivo nel sistema. E' cio' che viene definito demon, cioe' demone. Non appena viene inserito un CD-Rom ad esempio, tale programma si attiva ed effettua il mount del dispositivo. Una volta estratto il CD-Rom il demone effettua l'operazione inversa e cioe' l' umount. Occorre precisare che un sistema Linux puo' essere configurato in modo da effettuare le operazioni di mount che si rendono necessarie in fase di bootstrap, cioe' in fase di avvio. Come gia' detto con il comando mount occorre specificare il tipo di dispositivo che si vuole collegare al sistema. I vari dispositivi utilizzabili in un sistema Linux sono contenuti all'interno della directory di sistema /dev (dove dev sta per devices, cioe' dispositivi appunto). Ciascun dispositivo ha un nome ben preciso sotto Linux, ad esempio i floppy disk si chiamano fd (floppy disk appunto) gli hard disk hd (hard disk) i CD-Rom hd (gia' i CD-Rom sono visti come gli hard disk) e via dicendo. Se sono presenti piu' dispositivi dello stesso tipo vengono enumerati usando una cifra finale. Cioe' non e' vero per gli hard disk ed i CD-Rom che vengono enumerati usando una lettera finale. Ad esempio il primo disco del sistema sara' hda mentre un disco supplementare sara' hdb. Se il sistema contiene 2 dischi ed un CD-Rom allora il CD-Rom sara hdc. I dischi fissi possono essere divisi in partizioni. Ogni partizione e' contraddistinta da un numero pertanto se il primo disco del sistema contiene diciamo 3 partizioni, tali partizioni si chiameranno hda1, hda2 e hda3. Se oltre al primo disco viene collegato un CD-Rom, tale dispositivo sara' hdb. Supponendo di voler collegare un floppy disk al sistema, occorrera' usare il seguente comando: mount /dev/fd0 /mnt/floppy con tale comando viene collegato il filesystem contenuto nel floppy al filesystem generale del sistema a partire dalla directory /mnt/floppy. In realta' si poteva collegare tale dispositivo alla directory /home/miodisco o alla directory /pippo, ma per convenzione le operazioni di mount vengono effettuate collegando i vari dispositivi all'interno della directory /mnt (mnt sta per mount appunto). Pertanto la directory /mnt solitamente conterra' al suo interno delle sottodirectory come floppy, cdrom etc. Se il dispositivo che si vuole collegare al sistema contiene un filesystem diverso da quello utilizzato da Linux occorre allora specificare il tipo di filesystem usato. Se ad esempio il floppy disk che intendiamo collegare contiene dei dati scritti in ambiente DOS/Windows occorre specificare 'vfat' come tipo di filesystem. Per specificare il tipo di filesystem occorre usare l'opzione -t (type cioe' tipo) del comando mount: mount -t vfat /dev/fd0 /mnt/floppy All'interno di un sistema Linux sono generalmente presenti piu' partizioni e magari esiste una partizione che contiene un sistema Windows. Tipicamente in un sistema Linux esistono almeno due partizioni, la partizione di swap e la partizione di root. Per collegare tutte queste partizioni al sistema si puo' ovviamente usare il comando mount, ma poiche' si tratta di una operazione ripetitiva che va eseguita ad ogni avvio del sistema, si puo' in realta' effettuare il mount automaticamente configurando un apposito file di sistema che si chiama fstab (file system table) presente all'interno della directory di sistema /etc. Ogni partizione o dispositivo presente nel file fstab viene collegato con il relativo comando di mount automaticamente all'avvio del sistema e scollegato con il corrispondente comando di umount in fase di chiusura del sistema. Come gia' visto precedentemente per creare una partizione all'interno di un disco occorre usare il comando fdisk. Una volta creata la partizione occorre creare il filesystem con il comando mkfs (MaKe FileSystem, cioe' crea il filesystem). In fase di avvio del sistema viene eseguito il comando mount -a presente nel file /etc/rc.d/rc.sysinit. In questo file sono contenuti tutti i comandi che vengono eseguiti in fase di avvio del sistema. Il comando mount -a viene a conoscenza dei dispositivi da collegare leggendoli dal file fstab. I comandi da eseguire in fase di inizializzazione del sistema non sono sempre presenti nel file /etc/rc.d/rc.sysinit in quanto il nome di tale file varia da distribuzione a distribuzione. Se infatti parliamo di distribuzioni Red Hat allora il file e' /etc/rc.d/rc.sysinit appunto, ma se parliamo ad esempio di distribuzioni Slackware il file si chiama /etc/rc.d/rc.local. Il file fstab contiene una riga per ogni dispositivo da collegare in fase di avvio del sistema. Ogni riga e' composta da 6 colonne. La prima colonna indica il device, cioe' il dispositivo da collegare e puo' essere contenere valori come /dev/hda3, /dec/fd0 o /dev/hdc. La seconda colonna indica il punto di mount (o mountpoint) cioe' la directory che fungera' da radice per il dispositivo e puo' contenere valori come /mnt/floppy /mnd/cdrom /mnt/windows e cosi' via. La terza colonna contiene il tipo di dispositivo (filesystemtype) e puo' contenere valori come ext2, iso9660, swap, vfat e via dicendo. La quarta colonna specifica alcune possibili opzioni (options) e puo' contenere valori come defaults, ro, noauto e via dicendo. La quinta colonna contiene un valore usato dal comando dump ed infine la sesta colonna contiene un valore usato dal comando fsck per sapere se il dispositivo deve essere verificato o meno ed in quale ordine (il comando fsck infatti sta per FileSystem CheK, cioe' controllo del filesystem e viene usato per verificare la presenza di eventuali errori nel file system). Per saperne di piu' sul file fstab consultare la documentazione Linux (si parlera' di documentazione Linux nell'apposito capitolo in seguito). 10.9 L'archiviazione dei file: i comandi tar e gzipIl comando tar e' stato creato originariamente per archiviare file e directory su nastro (tar infatti sta per Tape ARchive cioe' archivio su nastro) ma in realta' con tale comando e possibile creare degli archivi su qualsiasi dispositivo. Ecco perche' ancora oggi e' molto usato anche su dispositivi diversi dai nastri. Con il comando tar e' possibile creare degli archivi che contengono file ma anche intere directory. E' possibile modificare un archivio creato con il comando tar aggiungendo nuovi file od eliminandone alcuni gia' presenti. Il comando tar percio' e' molto utile per effettuare dei backup. Un archivio creato con il comando tar ha solitamente come estensione '.tar' ma in realta' si tratta di una convenzione che non e' affatto obbligatoria. La sintassi del comando tar e': tar opzioni nomearchivio.tar file-e-o-directory. Le opzioni specificate con il comando tar non devono essere precedute da un trattino al contrario di tutti i comandi Linux. Ad esempio il comando:
tar cf mioarchivio.tar pippodir
crea un archivio chiamato mioarchivio.tar aggiungendo all'interno tutti i file presenti sotto la directory pippodir. Per estrarre
tutti i file e le directory contenute nell'archivio mioarchivio.tar occorre usare lo stesso comando tar ma con le opzioni
di estrazione:
tar xf mioarchivio.tar
Il comando tar non esegue alcuna compressione sui file aggiunti nell'archivio, tuttavia e' possibile creare un archivio
contenente file e directory e comprimerlo in modo da occupare meno spazio. Per far cio' occorre usare l'opzione z.
L'opzione z chiama il comando gzip che effettua la compressione dei file:
tar cfz mioarchivio.tar pippodir
Il file cosi' creato verra' chiamato mioarchivio.tar.gz. Saranno cioe' presenti 2 estensioni: .tar e .gz. Un file con
estensione .gz e' un file compresso e lo si puo' decomprimere usando il comando gzip. Per estrarre i file e le directory
contenute nel file mioarchivio.tar.gz occorre prima decomprimere l'archivio con il comando gzip e successivamente estrarre
i file dall'archivio con il comando tar. Per decomprimere un file compresso si puo' usare il comando gzip con l'opzione -d
oppure si puo' usare il comando gunzip. Nell'esempio precedente, per ripristinare i file originari si dovranno eseguire
i seguenti comandi:
gzip -d mioarchivio.tar.gz (oppure gunzip mioarchivio.tar.gz) e successivamente:
Parlando dei comandi mount ed umount abbiamo visto che le unita' di memorizzazione dei dati vengono definite dispositivi
(o devices). Oltre a tali unita' pero', esistono molti altri dispositivi come i terminali, i modem e le stampanti.
All'interno della directory /dev (devices appunto) sono presenti i vari dispositivi utilizzabili da Linux. Si tratta di
file speciali di sistema chiamati 'file di device'. Il file di device e' un' interfaccia tra Linux ed hardware. Come
gia' visto nel capitolo dedicato all'hardware, ogni dispositivo hardware 'dialoga' con il sistema operativo attraverso
uno speciale programma chiamato driver. Il driver e' un programma molto specializzato scritto generalmente dalle stesse
societa' produttrici di hardware. In Linux il sistema operativo non dialoga direttamente con i vari driver di ciascun
dispositivo hardware ne' tantomeno con l'hardware stesso, ma utilizza i file speciali contenuti nella directory /dev.
Ad esempio, per scrivere su un floppy disk presente nel drive A: Linux utilizza il file di device /dev/fd0.
In questo file di device un numero primario (o Major number) indica il tipo di dispositivo (e di conseguenza il driver da chiamare) mentre il numero secondario (minor number) indica univocamente una unita' fisica del sistema del tipo descritto
dal numero primario (il numero secondario viene passato come parametro al driver). I file di device possono essere di 2 tipi:
a carattere o a blocchi. I device a carattere vengono letti o scritti sequenzialmene un carattere per volta (come ad
esempio le porte seriali) mentre i device a blocchi vengono letti a blocchi di 1024 caratteri per volta (ad esempio
gli hard disk).
Ecco alcuni device presenti nella directory /dev:
fd0 Primo lettore di dischetti
Ecco un esempio di device:
$ ls -l /dev/hda
dove 3 e' il numero primario e 0 e' il numero secondario.
Il nome di un file rappresenta un riferimento ad un punto all'interno del disco dove sono memorizzati i dati
contenuti nel file stesso. In realta' sarebbe piu' corretto dire che ad ogni nome di file viene associato l'i-node
del file stesso. Cioe', per ogni file esiste una coppia 'nome del file'/i-node.
Capiremo questa affermazione in seguito parlando degli i-node, per ora e' possibile comprendere il concetto
pensando agli handle: chi conosce qualche linguaggio di programmazione orientato agli oggetti sa benissimo di cosa
si sta parlando. Handle significa 'maniglia', infatti un handle e' una sorta di maniglia, cioe' uno strumento per
maneggiare degli oggetti. Non e' ancora chiaro? Ecco l'esempio per la massaia: la padella! Supponiamo di possedere
una padella senza manico...supponiamo anche di voler preparare una gustosa frittata alle verdure (personalmente
adoro i peperoni) ;o) Ok, mescoliamo gli ingredienti, mettiamo la padella sulla macchina del gas, accendiamo il fuoco
ed aspettiamo. Ecco ora e' pronta la frittata, occorre versarla nei piatti...ma...accidenti, la padella non ha il
manico! Chi si azzarderebbe a toccarla in questo momento? Hmmm...senza manico, occorrono come minimo delle presine
o dei guanti da forno...gia' gli handle! ;o) Ecco, per 'afferrare' un file che si trova su un disco, un CD-Rom,
un floppy disk o chissa' dove, occorre un manico, una presina, un guanto da forno o meglio un handle: il suo nome appunto.
Il nome di un file e' il suo handle, cioe' la maniglia con la quale maneggiare il file. Nei mondi *nix (*nix sta per
Unix, Linux, Aix, Minix et similia) esiste il concetto di link. Il collegamento tra il nome del file e l'indirizzo fisico
dove si trova il file viene definito 'link' (che significa appunto collegamento). Cio' che abbiamo definito come handle,
nei mondi *nix viene chiamato link. Potremmo percio' definire un link ad un file come il suo nome. Usando il comando
ls:
ls -l pippo
possiamo notare un numero che precede il nome del proprietaro del file, che in questo caso e' mau.
Il numero precedente al nome del proprietario del file (1) e' il numero di link che tale file possiede.
In questo caso esiste un solo link: il nome del file stesso (pippo). Questa e' la situazione normale di un qualsiasi file.
Linux pero' mette a disposizione un comando che permette di creare ulteriori link allo stesso file. Creare un ulteriore link
percio' significa creare un ulteriore nome per referenziare il file o, se si preferisce, un ulteriore handle (o manico,
maniglia, presina, guanto da forno) ;o). Il comando che permette cio' e' il comando ln (LiNk, cioe' collegamento):
ls
Come si puo' vedere pippo e pippo2 hanno 2 come numero di link il che significa che pippo2 e' semplicemente un altro nome
che referenzia sempre lo stesso file. Attenzione: pippo2 non e' la copia di pippo ma si tratta proprio dello stesso file.
Se si modifica pippo e si visualizza il contenuto di pippo2 si notera' che pippo2 e' identico a pippo: infatti sono lo
stesso file. Se pippo2 fosse una copia di pippo, modificando pippo, pippo2 rimarrebbe invariato. Poiche' pippo2
e' un secondo nome dello stesso file, cancellando pippo sara' sempre possibile far riferimento al file usando pippo2.
Per tornare all'esempio della padella, quando si crea un link ad un file si sta aggiungendo un nuovo manico alla padella:
se se ne rompe uno, e' sempre possibile afferrare la padella usando l'altro manico. La padella diventa inusabile solo
quando non possiede piu' alcun manico. Tornando ai file, cio' significa che: un file viene cancellato effettivamente solo
quando vengono eliminati tutti i suoi link:
ls -l
Questo appena visto e' un 'link fisico'(hard link) e puo' ad esempio essere utile per far riferimento ad un file da una directory
diversa da quella all'interno della quale si trova il file. Ad esempio, il file pippo potrebbe risiedere nella directory /home/mau
mentre il link pippo2 potrebbe risiedere nella directory /home/francesca. Si potra' accedere al file pippo dalla directory /home/mau
oppure dalla directory /home/francesca usando il riferimento pippo2:
pwd (visualizzo la directory corrente: /home/mau)
pippo2 non e' la copia di pippo: modificando pippo nella directory /home/mau e visualizzando pippo2 nella directory
/home/francesca, noteremo che pippo2 conterra' le modifiche fatte a pippo: infatti sono due nomi che referenziano
lo stesso file. Come e' possibile scoprire se pippo e pippo2 sono lo stesso file o file diversi? Visualizzando il
numero di i-node di entrambi i file usando il comando ls e l'opzione -i:
ls -i pippo pippo2
ls -i visualizza il numero di i-node (-i sta per i-node appunto). In questo esempio vediamo che pippo e pippo2 hanno
lo stesso i-node: possiamo essere certi che si tratta dello stesso file, in quanto per ogni file esiste un solo i-node
e ad ogni i-node e' associato un solo file. Ma se e' possibile creare un secondo nome (od un terzo, un quarto e cosi' via)
per un file comune, non e' possibile dare piu' nomi ad una directory. Per essere piu' corretti in verita' occorre dire
che non e' possibile creare un link fisico ad una directory, ma e' possibile crearne uno simbolico. Un link simbolico
non e' un nome aggiuntivo ma e' un file speciale che contiene al suo interno il puntatore al file, o meglio, il
percorso da fare per raggiungere il file. Per creare un link simbolico occorre usare il comando ln con l'opzione -s:
ln -s pippo pippo2
questo comando crea un link simbolico, cioe' un file speciale che contiene il percorso del file originario. Per evidenziare
cio' si puo' usare il comando ls con le opzioni i ed l:
ls -il pippo pippo2
Hmmm, come si puo' vedere il comando ln con l'opzione -s crea un nuovo file mentre il comando ln senza opzioni
crea un secondo nome ma non un secondo file. Cio' lo si evince esaminando il numero di i-node: il file pippo ha i-node
15436 mentre il file pippo2 ha i-node 15437. Si tratta a tutti gli effetti di 2 file diversi. Inoltre possiamo notare
che le dimensioni dei due file sono diverse: 553 byte il file pippo e 5 byte il file pippo2. Una differenza ulteriore
e' il carattere che identifica il tipo di file: nel file pippo e' presente un trattino (file comune) nel file pippo2
e' presente la lettera l (link). Infine, alla fine della riga relativa al file pippo2 e' presente una informazione
ulteriore: una freccia che indica il collegamento tra pippo2 e pippo. La conseguenza piu' immediata di tutto cio'
e' che cancellando pippo, pippo2 puntera' ad un file inesistente.
ls -li
cercando di visualizzare il file originario usando il link simbolico pippo2 otterremo un messaggio di errore dalla shell:
no such file or directory. Il link ora punta ad un file che non esiste piu' in quanto e' stato cancellato.
A parte questa differenza, in quali casi e' utile usare un link simbolico? Ad esempio quando si vuole creare un link
ad una directory oppure quando si vuole creare un link ad un file o ad una directory che si trova all'interno di un filesystem diverso.
Con un link simbolico infatti e' possibile far riferimento ad un file che si trova in un dispositivo diverso o addirittura in un filesystem diverso.
A questo punto e' il caso di esaminare in maggiore dettaglio questo fantomatico i-node. A dire il vero non e' indispensabile conoscere il filesystem ext2 in dettaglio ma le informazioni che seguono sono utili a mio avviso per capire a fondo il significato di link fisico e di link simbolico: il lettore non troppo curioso puo' decidere di saltare questo paragrafo
e passare al capitolo successivo. Ma torniamo all'i-node. L'i-node e' una struttura presente nel filesystem ext2 ed in altri filesystem *nix. Esistono vari filesystem come ad esempio ext2 (extended 2), fat (file allocation table), nfs (network file system), hfs (hierarchical file system) e molti altri. Linux (a differenza di altri sistemi operativi) supporta un gran numero di filesystem diversi. Ma cosa e' un filesystem? Un filesystem e' una architettura che comprende i metodi e le strutture dati usate da un sistema operativo per memorizzare i file su un supporto fisico. Ogni sistema operativo possiede un determinato filesystem. Ad esempio i sistemi macintosh usano hfs, mentre i sistemi dos/windows usano fat. Linux puo' usare vari filesystem come ad esempio ext, ext2, ext3 o reiserfs, ma supporta anche i filesystem di sistemi operativi diversi. Il filesystem piu' diffuso in ambito Linux e' attualmente ext2, vediamolo in dettaglio. Il filesystem ext2 e' suddiviso in piu' parti chiamate cylinder group. Ogni cylinder group e' un pezzo di disco a se' stante questo affinche' in caso di problemi con un cylinder group, tutti gli altri possano essere ancora utilizzabili. L'utilita' dei cylinder group e' anche quella di poter ridurre i tempi di accesso ai file, memorizzando i file e le directory che li contengono all'interno dello stesso cylinder group. All'interno di ogni cylinder group sono presenti varie tabelle e strutture. Un struttura abbastanza importante si chiama super_block e contiene varie informazioni come le caratteristiche e le dimensioni del filesystem stesso nonche' alcune variabili di stato (blocchi liberi, numero di mount effettuati etc). Ecco un super_block in dettaglio:
/*
Tra le varie informazioni sono presenti un contatore di i-node, un contatore di blocchi e la dimensione di ogni blocco.
Data l'importanza di questa struttura, essa viene duplicata all'interno di ogni cylinder group, in modo da poter
disporre di copie di riserva in caso di errori e di problemi. All'interno di ogni cylinder group sono presenti inoltre
un group descriptor, una block bitmap, una i-node bitmap ed una i-node table. Il group descriptor contiene informazioni
di controllo relative all'intero gruppo:
struct ext2_group_desc {
Un elemento importante all'interno del group descriptor e' il puntatore al blocco che contiene la tabella degli i-node.
La block bitmap e' una mappa di bit dove ogni bit indica quali blocchi sono allocati. La i-node bitmap indica gli i-node allocati e la i-node table contiene gli i-node che appartengono a quel cylinder group. Su Linux i dati vengono memorizzati all'interno di blocchi di 1024 byte (ma possono anche diventare 2048 o 4096). Si tratta di blocchi logici in quanto solitamente i blocchi fisici di un disco sono lunghi 512 byte (un blocco logico contiene 2 o piu' blocchi fisici).Il blocco
e' l'area minima allocabile sul disco. In altre parole se un file e' lungo 10 byte verra' allocato un blocco logico mentre se e' lungo ad esempio 2000 byte verranno allocati 2 blocchi. Abbiamo detto che la i-node table contiene l'elenco degli i-node all'interno del cylinder group, ma cosa e' un i-node? Si potrebbe definire l'i-node come la carta di identita' di ogni file. Infatti l'inode e' una struttura che contiene gli attributi e le caratteristiche del file a cui e' legato (i-node sta per information node, cioe' nodo di informazione). Esiste un i-node per ogni file. Ogni i-node e' identificato da un numero univoco. All'interno di questa struttura troviamo le seguenti informazioni: i permessi di accesso al file, l'identificativo del proprietario del file, le dimensioni in byte, la data dell'ultimo accesso al file, la data di creazione, la data dell'ultima modifica, la data di cancellazione, l'identificativo del gruppo, un contantore dei link ed un contatore dei blocchi. Ogni i-node inoltre, possiede una tabella di puntatori ai blocchi che contengono i dati del file. Ecco una parte della struttura dell'i-node:
struct ext2_inode {
Per semplicita' non esaminiamo il resto della struttura che contiene tra l'altro una tabella di 15 puntatori a blocchi:
__u32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
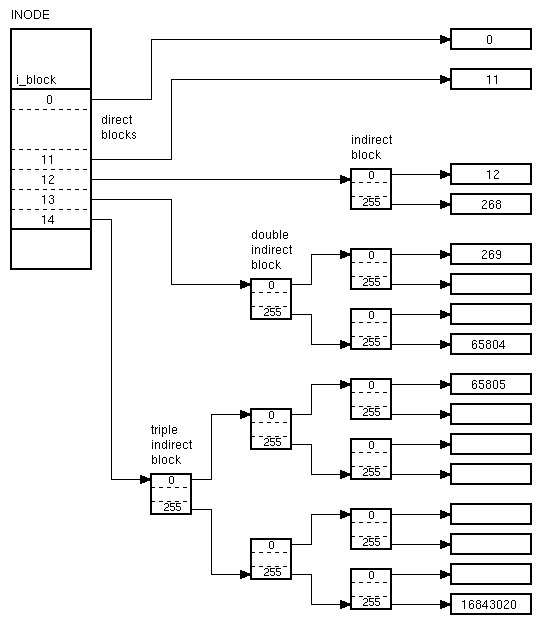
Il primo elemento della struttura (i_mode) contiene tra l'altro il tipo di file (comune, directory, speciale etc) ed i permessi di accesso al file (read, write, execute). Un altro elemento importante e' la tabella di puntatori ai bloccchi (i_block). Come visto in precedenza un file puo' essere spezzato in piu' blocchi logici da 1024 byte ciascuno. La tabella di puntatori ai blocchi del file e' costituita da 15 elementi. Ogni elemento contiene un puntatore ad un blocco. Poiche' 1024 x 15 = 15360, si potrebbe pensare che la lunghezza massima di un file debba essere di 15360 byte, ma non e' cosi'. Infatti i primi 12 elementi della tabella contengono in effetti un puntatore ad un blocco di dati ciascuno chiamato direct block, ma le cose cambiano dal tredicesimo elemento in poi. Infatti nell'elemento 13 della tabella dei puntatori ai blocchi contiene un puntatore ad un blocco che non contiene dati ma un'altra tabella di puntatori. Questo blocco si chiama indirect block. All'interno di questa tabella ogni elemento contiene un puntatore ad un blocco di dati.
L'elemento 14 contiene un puntatore ad un blocco di puntatori che a loro volta non puntano a blocchi di dati (a differenza
di quelli puntati dal puntatore dell'elemento 13) ma puntano ad altri blocchi di puntatori. Questi ultimi blocchi di puntatori puntano a blocchi di dati. Il blocco di puntatori puntato dal puntatore dell'elemento 14 si chiama double indirect block. Infine l'elemento 15 della tabella di puntatori ai blocchi contenuto nell'i-node punta ad un blocco di puntatori chiamato triple indirect block. Il blocco triple indirect block punta ad un blocco di puntatori ognuno
dei quali punta ad un altro blocco di puntatori ognuno dei quali punta ad un blocco di dati. Poiche' ogni blocco logico
generalmente e' lungo 1024 byte e poiche' nei sistemi con registri a 32 bit un puntatore ad interi occupa 4 byte (4 byte da 8 bit ciascuno significano 4 x 8 = 32 bit, come ben sa chi programma in linguaggio C) se ne deduce che 1024 / 4 = 256, cioe' ogni blocco di puntatori puo' contenere 256 puntatori a blocchi. Ad ogni modo l'immagine seguente chiarisce l'intero sistema di puntatori a blocchi:
Vediamo infine la struttura delle directory. Una directory e' un file speciale che contiene al suo interno delle informazioni
relative ai file che contiene. Vediamo la struttura di una directory:
#define EXT2_NAME_LEN 255
Ogni directory possiede una tabella all'interno della quale esiste una coppia di elementi che contengono rispettivamente il nome del file (char name[EXT2_NAME_LEN]) e l'i-node associato (__u32 inode;). Ogni all'interno di una directory possiede una coppia di elementi. Esistono tante coppie quanti sono i file contenuti all'interno della directory. Quando viene creato un link fisico ad un file non viene fatto altro che inserire una nuova coppia di elementi:
ls
la directory corrente contiene 3 file: pippo, pluto e topolino. Cio' significa che la tabella di tale directory conterra'
3 coppie di elementi:
pippo 10500 (i-node numero 10500)
se creiamo un link al file pippo con il comando 'ln pippo pippolink' il sistema aggiungera' una quarta coppia all'interno
della tabella:
pippo 10500 (i-node numero 10500)
come possiamo vedere sia a pippo che a pippolink e' associato l'i-node numero 10500. Possiamo pertanto asserire che
ogni volta che si crea un link ad un file il sistema non fa altro che creare una nuova entrata (entry) cioe' una nuova
coppia "nome file"/i-node all'interno della tabella della directory. Il filesystem ext2 puo' avere una dimensione massima
di 4 terabyte, ciascun file puo' avere una dimensione massima di 2 gigabyte ed il nome di ogni file puo' essere lungo
al massimo 255 caratteri.
Il filesystem ext2 a differenza di ext3 e di reiserfs e' un filesystem non journalled. Cosa e' il journalling?
Come abbiamo visto all'interno di un filesystem i dati vengono scritti all'interno di blocchi e successivamente vengono
aggiornate tutte le relative tabelle e strutture (come gli i-node ad esempio). Quando viene effettuato lo shutdown del
sistema, Linux scrive su disco tutti i dati che erano presenti nelle aree di lavoro, successivamente aggiorna le varie
strutture e tabelle del filesystem ed infine 'smonta' i dischi e le partizioni. Al successivo avvio il sistema monta
nuovamente dischi e partizioni e verifica tutte le strutture del filesystem: se tutto e' in ordine avvia tutti i processi
del sistema. Tutto cio' accade in situazioni normali. Il problema si pone in situazioni anomale, ad esempio in caso di
improvvisa mancanza di corrente o di crash di sistema. Cosa accade in tali circostanze? Cadendo improvvisamente la tensione
o grazie ad un crash, il sistema non e' in grado di memorizzare i dati presenti nelle aree di lavoro (in memoria) e
di aggiornare le strutture del filesystem, percio' e' costretto ad effettuare una scansione completa del disco per
rilevare eventuali errori o situazioni rimaste in sospeso. Questa operazione e' tristemente nota a tutti gli utilizzatori
dei sistemi Windows in quanto a seguito di un crash di sistema al successivo avvio parte il famoso programma scandisk... ;o)
Ad ogni modo questa scansione del disco richiede tempo e non elimina il problema della possibile perdita dei dati relativi
agli ultimi aggiornamenti che si stavano effettuando prima della chiusura anomala del sistema. Il sistema del journalling
offre una soluzione a questi problemi. Con il journalling viene creata una nuova struttura all'interno del filesystem:
il journal. Il journal e' una sorta di diario dove viene inserita una nuova entrata prima di effettuare una
modifica su disco. Questo sistema permette di tenere traccia delle ultime modifiche effettuate. In caso di crash del
sistema o di interruzione di corrente elettrica al successivo riavvio il sistema effettua il controllo del filesystem pero'
con una differenza: non viene piu' effettuata una scansione dell'intero disco (operazione che su grossi dischi puo'
richiedere parecchi minuti) ma, utilizzando il journal, controlla solamente le parti del filesystem relative alle ultime
modifiche (operazione che richiede pochi secondi). Per maggiori informazioni riguardo il filesystem consultare il relativo
howto all'indirizzo:
http://www.penguin.cz/~mhi/fs/Filesystems-HOWTO/Filesystems-HOWTO.html
Inizio della guida
Linux: generalita'
Indice
La shell BASH
Copyright (c)
2002-2003 Maurizio Silvestri |